Most discussions of LLM evaluation ask which evaluator is best.
I think that is the wrong first question.
Some tasks need judgment. Others need verification. A rubric can help decide whether an explanation is clear, persuasive, or useful. It is a poor substitute for test cases when evaluating code. Likewise, exact checks are not enough when the output is inherently qualitative.
That distinction is the motivation behind
llm-as-an-oracle.
An Oracle, in this setting, is not an all-knowing model. It is an adaptive
evaluation layer that decides whether a task should be evaluated by an
LLM-as-a-Judge or an LLM-as-a-Verifier.
The central claim is simple:
Evaluation should be routed to the strategy that best matches the structure of the task.
Here is why that matters in practice. Later in this post, three agents fix the
same N+1 query bug. Two of them change the query shape. The third wraps the
buggy call in an lru_cache and looks correct — familiar technique, concrete
code, a plausible performance story. A Judge scoring on presentation alone can
be fooled by it. A Verifier running the test suite cannot. That gap between
looking right and being right is the reason this router exists.
That sounds obvious once stated plainly, but it is easy to violate in practice. As soon as a benchmark, agent workflow, or production evaluation pipeline standardizes on a single evaluator, it begins to treat fundamentally different tasks as though they required the same kind of evidence.
The evaluation problem
Human evaluation remains the reference point for many LLM systems. It is often the most flexible form of assessment because humans can interpret incomplete instructions, account for context, distinguish severity from style, and notice when a candidate answer is technically correct but pragmatically poor. It also scales badly, which created demand for automated evaluation. Traditional metrics can be useful, but they are narrow:
- exact match is valuable when the answer space is constrained
- unit tests are valuable when executable behavior matters
- overlap metrics can be useful in narrow summarization settings
- preference labels can summarize subjective quality
None of these solves the broader evaluation problem on its own.
The rise of capable instruction-following models created a new option:
LLM-based evaluators. This has produced a family of LLM-as-* patterns:
LLM-as-a-JudgeLLM-as-a-VerifierLLM-as-a-CriticLLM-as-a-Ranker
These ideas have appeared across several lines of work on model-based judging, verification, critique generation, and ranking. 1
These patterns are often discussed as alternatives. I think they are better understood as evaluation modes with different operating assumptions.
The question is not merely whether LLM evaluators are useful. The more precise question is:
Which evaluator is appropriate for this task, given the evidence available?
Judge and Verifier solve different problems
The easiest way to understand the Oracle idea is to first separate the two evaluation strategies it routes between.
LLM-as-a-Judge
An LLM-as-a-Judge performs holistic evaluation. It reads the task, candidate
trajectory, and evaluation criteria, then emits a score or preference. This is
the natural fit when the target quality is open-ended, subjective, or otherwise
difficult to reduce to executable checks. 2
Typical Judge-friendly questions include:
- Is this answer concise without omitting important details?
- Does this explanation match the user’s level of expertise?
- Which recommendation is more useful under vague constraints?
- Is the reasoning persuasive and coherent?
The Judge pattern is valuable because many real tasks do not collapse cleanly into executable checks. They require interpretation.
In llm-as-an-oracle, the Judge strategy supports:
- rubric-driven scoring
- pointwise trajectory scoring
- pairwise comparisons
- order-swapped pairwise evaluation to reduce positional bias
- aggregation across multiple criteria
These details matter because a Judge is not merely “ask another model what it thinks.” A useful Judge has structure around how scores are produced and how comparisons are stabilized.
For example, a Judge can score each trajectory against several weighted criteria, then use pairwise comparisons only when two candidates are close. If the pairwise order is swapped and averaged, the system can reduce simple positional bias without pretending that the evaluator has become objective. 2
LLM-as-a-Verifier
An LLM-as-a-Verifier is better suited to tasks where stronger evidence exists.
It is appropriate when candidate trajectories can be evaluated against signals
that are closer to correctness than preference.
3
Typical Verifier-friendly tasks include:
- code generation with tests
- question answering with reference answers
- tool-use traces with expected outputs
- structured reasoning tasks with decomposable criteria
- tasks where execution evidence is available
The Verifier strategy in this project is designed around:
- finer-grained score extraction
- repeated verification
- criteria decomposition
- pairwise tournament-style ranking
- support for logprob-aware scoring when the provider exposes token probabilities
That last point is important. A Verifier tries to squeeze more discriminative signal out of the evaluator than a single coarse score can provide.
The Judge is asking which answer seems better under a rubric; the Verifier is asking which trajectory survives the strongest evidence-sensitive checks available. Related questions, but not the same one.
What the Oracle adds
If Judge and Verifier are both useful, a natural response is to expose both and let the caller choose. That’s necessary but not sufficient. Many workflows mix task types:
- an agent may produce code patches, explanations, and planning notes
- a benchmark may combine factual QA, long-form reasoning, and executable tasks
- a production system may need to evaluate recommendations, SQL, and tool calls within the same pipeline
In those settings, asking the caller to manually select an evaluator every time creates friction and invites inconsistency.
The Oracle layer addresses that problem.
Its job is to:
- inspect the task and trajectories
- extract signals about the task structure
- decide which evaluator is the better fit
- execute only that strategy
- return both the result and the routing explanation
The Oracle is therefore not a third evaluator. It is a decision layer above the two evaluators.
Anatomy of the Oracle router
The default router in llm-as-an-oracle is deterministic. It does not call an
LLM to decide which evaluator to use. Instead, it extracts interpretable signals
and applies a fixed chain of routing policies.
That design choice is intentional. The system should make evaluator selection more legible, not less.
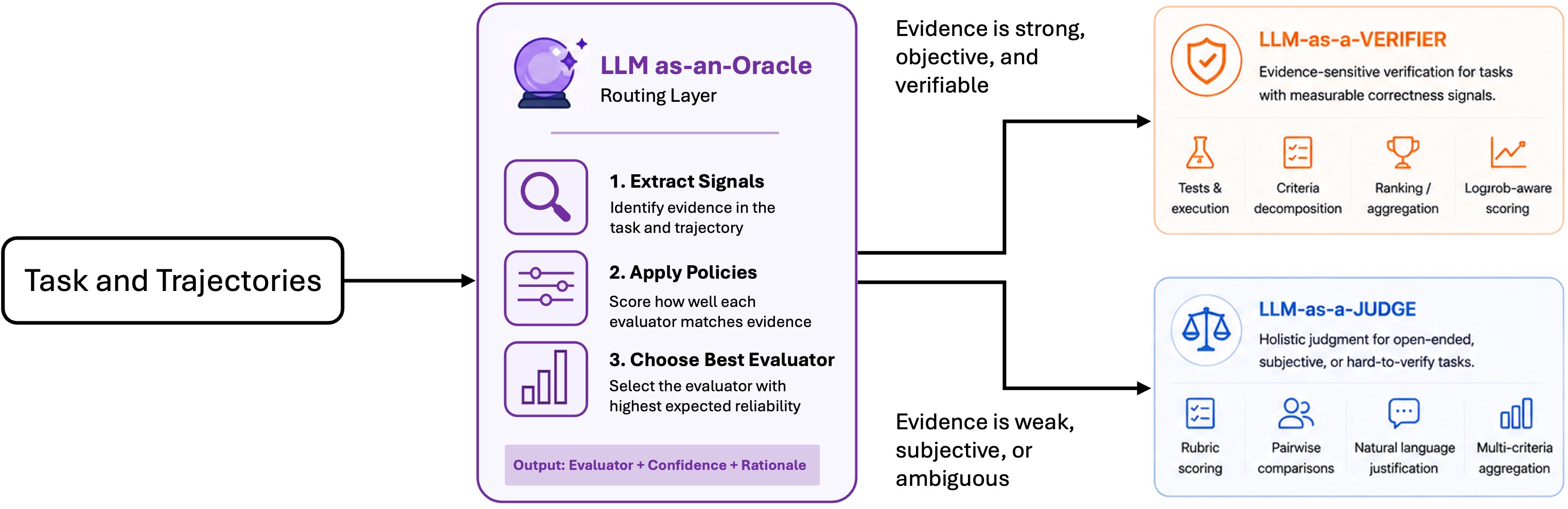
Step 1: extract routing signals
The router converts the task and trajectories into a structured set of signals. The current implementation uses features such as:
has_ground_truthhas_test_casestrajectory_countstated_difficultyverifiable_keyword_densityjudgment_keyword_densityproblem_lengthoutput_availableprior_hardness
These features encode simple but meaningful intuitions.
For example:
- ground truth and test cases usually favor verification
- execution output usually favors verification
- open-ended language often favors judgment
- a previously observed hard task may deserve a stronger verification path
The goal is not to perfectly infer task type from text. The goal is to make the selection logic explicit enough to inspect, revise, and extend.
Step 2: collect policy votes
Signals are passed through a chain of policies. The default router uses policies that reason about:
- prior hardness
- available ground truth
- keyword/domain cues
- task difficulty
- output availability
- trajectory count
Each policy casts a weighted vote for either Judge or Verifier.
Conceptually:
Ground truth present? -> favor Verifier
Execution output available? -> favor Verifier
Open-ended wording? -> favor Judge
Very low routing confidence? -> fall back to Judge
The implementation is more nuanced than that sketch, but the spirit is the same. Evaluation mode is chosen by accumulating evidence.
Step 3: aggregate confidence
The router aggregates weighted policy votes into a final confidence score. The winning strategy is selected only if its confidence is strong enough. Otherwise, the system falls back to the more general-purpose Judge path.
This creates an important separation:
- a strategy can be powerful
- the router can still decide that the available evidence does not justify using it for this particular task
That is a better design than letting every downstream evaluator silently assume the task is well suited to its own strengths.
Step 4: expose the routing trace
The output of a routing decision includes:
- the selected strategy
- the final confidence
- the raw signals
- every policy vote
- a human-readable reasoning trace
I care about this part the most, because evaluation pipelines already accumulate ambiguity. A score without a path to understanding how it was obtained is hard to debug. The Oracle makes one critical source of ambiguity observable: why this evaluator was chosen in the first place.
Evaluating trajectories, not just answers
The project uses the term trajectory deliberately.
A trajectory is a candidate task-solving attempt. It may contain:
- the final answer
- intermediate reasoning or planning
- code
- tool calls
- execution output
- an optional reward signal
This is especially relevant for agents. When a coding agent fixes a bug, the thing we care about is not only the final patch. We may care about:
- whether the patch addresses the requested failure mode
- whether it satisfies explicit requirements
- whether execution evidence supports the answer
- whether two superficially plausible solutions differ materially
For text-only tasks, evaluating the final answer may be sufficient. For agents, the evaluation object often needs to be richer.
The Oracle architecture assumes that richer object from the beginning.
A concrete example: the N+1 query bug
One example in the repository asks three agents to fix an N+1 query problem. The original function loads orders first, then issues one SQL query per order to load items. That means:
- 51 queries for 50 orders
- 5,001 queries for 5,000 orders
The task asks for a constant-query solution and provides both ground truth and test cases.
The original bug has this shape:
def get_orders_with_items(user_id: int) -> list[dict]:
orders = db.execute(
"SELECT * FROM orders WHERE user_id = ?",
[user_id],
)
for order in orders:
order["items"] = db.execute(
"SELECT * FROM items WHERE order_id = ?",
[order["id"]],
)
return orders
The loop is the problem. The first query fetches the orders, then each order triggers another query for its items.
Three candidate trajectories are evaluated:
- one rewrites the query with a
JOIN - one performs a batched prefetch with
WHERE IN - one adds an
lru_cachearound the inner item lookup
The first two are legitimate fixes, though they make different tradeoffs. The third sounds plausible because caching often improves performance. But it does not solve the stated problem. On a cold cache, query count still grows with the number of orders.
The misleading fix looks like this:
@lru_cache(maxsize=256)
def fetch_items(order_id: int) -> list[dict]:
return db.execute(
"SELECT * FROM items WHERE order_id = ?",
[order_id],
)
def get_orders_with_items(user_id: int) -> list[dict]:
orders = db.execute(
"SELECT * FROM orders WHERE user_id = ?",
[user_id],
)
for order in orders:
order["items"] = fetch_items(order["id"])
return orders
This may help repeated calls for the same order, but it does not change the first-run query pattern:
expected: query_count == O(1)
actual: query_count == 1 + number_of_orders
A real fix changes the query shape. For example, the JOIN trajectory uses one
SQL query and groups the rows afterward:
SELECT o.*, i.*
FROM orders o
LEFT JOIN items i ON i.order_id = o.id
WHERE o.user_id = ?;
This is exactly the sort of case where evaluator choice matters.
Why Judge alone is risky here
A holistic Judge may recognize that the cache-based answer is weaker. But it is also possible for that answer to benefit from surface plausibility:
- it uses a familiar optimization technique
- it contains concrete code
- it appears to address performance
If the score is driven too much by presentation quality, the wrong candidate can become competitive.
Why Verifier is the better fit
The task has stronger evidence:
- explicit correctness requirements
- test cases
- expected behavioral properties
- a measurable performance invariant: query count must not scale with
N
That is precisely the situation where the Oracle should route toward the Verifier. The evaluation problem is not mainly aesthetic. It is evidential.
The interesting part is not merely that Verifier can help. The more general point is that the Oracle can identify this task shape before evaluation begins.
Judge and Verifier are not rivals
It is tempting to treat this as a winner-take-all comparison:
- Verifier is more objective
- Judge is more flexible
- one must be superior
I do not think that framing is useful.
Each strategy fails differently.
Failure modes of Judge
A Judge can overvalue fluent or confident language, blur correctness and style, and struggle to separate close technical alternatives without stronger evidence.
Failure modes of Verifier
A Verifier has its own failure modes. It inherits bad ground truth, can overfit to incomplete criteria, becomes brittle when tests are narrow, and quietly underperforms on tasks that are fundamentally subjective.
The Oracle does not eliminate these problems. It tries to reduce one avoidable problem: choosing the wrong mode of evaluation for the task at hand.
When the Oracle should ask for help
There is another failure mode worth making explicit: sometimes the task itself is underspecified.
Suppose three architecture recommendations are all defensible, but the best one depends on a missing fact about team size, latency goals, compliance constraints, or deployment environment. No evaluator should pretend confidence if the information needed to decide was never supplied.
The fuller design in this project explores a Human Oracle escalation path for
those cases. When evaluation evidence runs out, the system can ask a targeted
clarifying question, incorporate the answer, and re-evaluate.
The point is not to put a person in the loop by default. It is to avoid manufactured certainty when a decision depends on missing context.
That same principle motivates the router itself:
- do not hide assumptions
- do not oversell confidence
- make uncertainty inspectable
What this suggests about evaluation design
The Oracle pattern leads to a broader design lesson.
Good evaluation systems share a few properties. Evaluator should match task structure: open-ended and evidence-grounded tasks are different, and treating them the same introduces avoidable error. Selection should be explicit, part of the system design rather than a hidden convention buried in notebook code or benchmark glue. Inspectability should be preserved: routing traces, criteria, and confidence should be artifacts you can actually look at. And the system should admit when evidence is insufficient. A strong evaluator is no substitute for missing context, and escalation can be the right move.
Where this pattern is useful
I think LLM-as-an-Oracle is especially relevant for:
- coding agents that generate several candidate patches
- benchmark pipelines that mix factual, creative, and executable tasks
- tool-using agents whose outputs include both text and action traces
- research workflows comparing evaluators across heterogeneous task families
- production systems that want one evaluation interface without pretending every task should be judged the same way
In all of those cases, evaluator selection is part of the problem.
Treating it as a first-class system component is cleaner than standardizing on a single evaluation method and compensating later with increasingly elaborate exceptions.
Closing thought
The evaluator should fit the task.
LLM-as-an-Oracle is my attempt to turn that principle into a concrete system:
route between judgment and verification, expose the reasons for the choice, and
leave room for human escalation when neither automated path has enough evidence.
-
Zheng et al. introduce
LLM-as-a-Judge; theLLM-as-a-Verifierframework develops evidence-sensitive verification;CritiqueLLMstudies critique generation for evaluation; and pairwise ranking prompting shows how LLMs can be used directly as rankers. https://arxiv.org/abs/2306.05685 https://llm-as-a-verifier.notion.site/ https://arxiv.org/abs/2311.18702 https://arxiv.org/abs/2306.17563 ↩ -
Zheng et al., “Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena,” 2023. https://arxiv.org/abs/2306.05685 ↩ ↩2
-
“LLM-as-a-Verifier: A General-Purpose Verification Framework.” https://llm-as-a-verifier.notion.site/ ↩